VOICE Live From CES に参加してきました(1)
CES2020 の2日目は Tech South で開催された VOICE Live From CES に参加してきました。

出典:VOICE SUMMIT
参加費は早割で$400でした。

会場は ARIA というホテルで、ラスベガスで一番新しいホテルのようです。他の会場(コンベンションセンター等)と異なり、ホテルは入口すぐにカジノがあります。そのため会場までの距離が少々遠いのが難点です^^;


ステージはこんな感じでした。
Contents
スケジュール
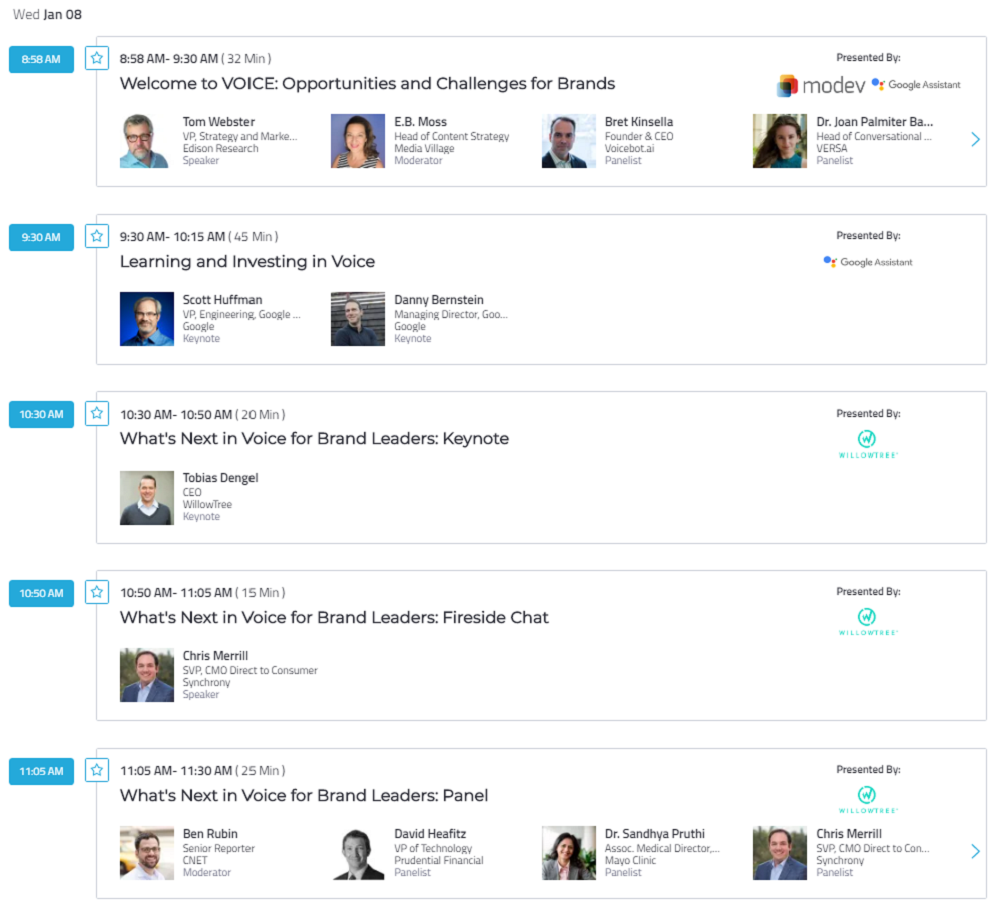
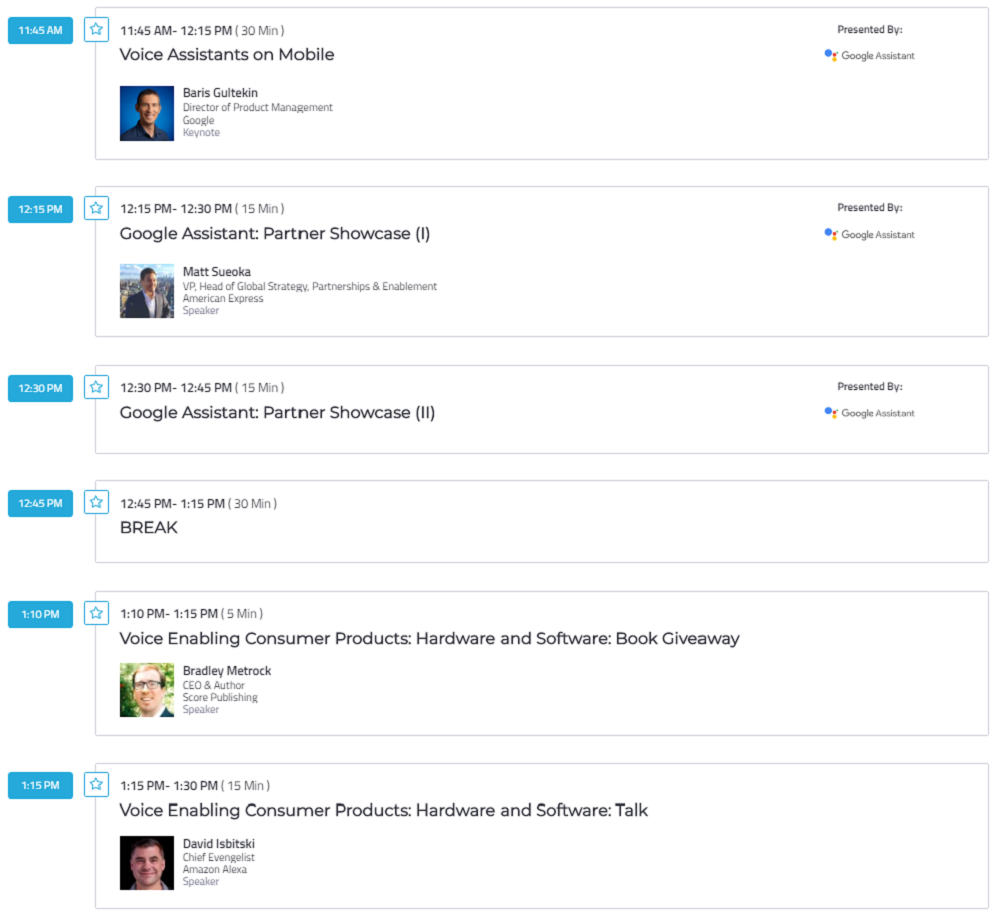
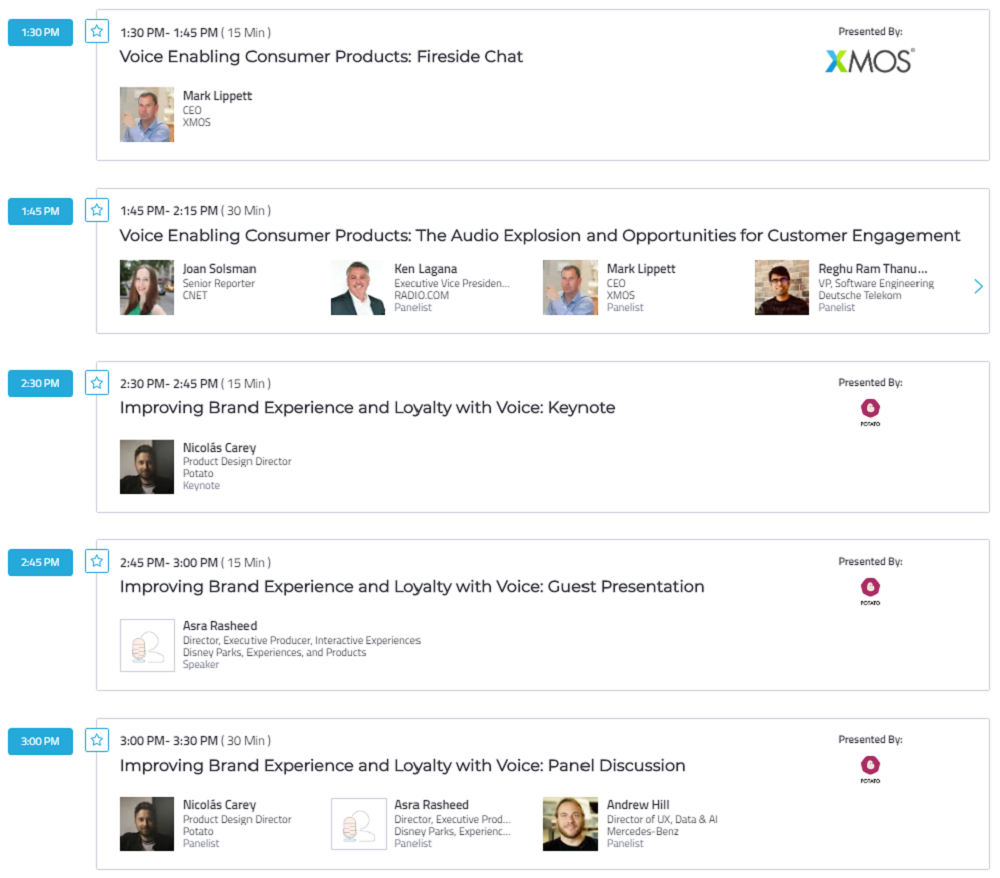
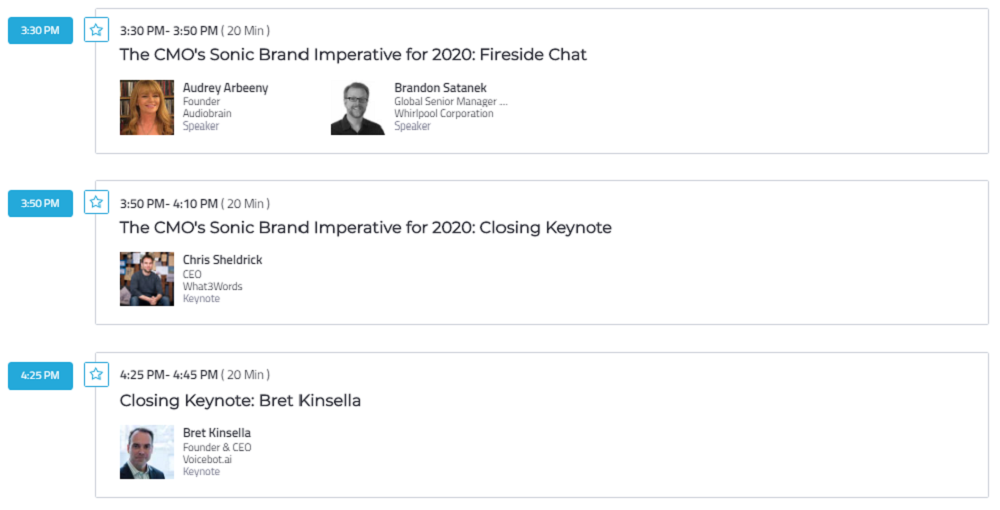
出典:VOICE SUMMIT
予定していたものと多少前後ありましたが、基本的には Keynote と Panel Discussion が交互に行われていました。Panel Discussion を英語で聞くのは中々難易度が高いですね…。そちらの方はあまり情報拾えていません(悲)
Learning and Investing (Google)
まずは Google の Scott Huffman さんの登壇。
Key Learnings
- Voice is about action
- Voice is demands conversation
- Voice drives daily routines
- Voice is universal

音声とは「アクション」である。頭の奥では分かっていたはずだけれど、初めて言葉として認識した気がします。アシスタントに話しかけるとき、何かしらのアクションを要求しているわけですよね。
How to think about 2020
- Screens will change everything
- You can start with what you already built
- Discoverability will require investment
Screens will change everything
まずは、後ほど別のセッションでも出てきますが、スクリーンがこれから重要になってくるというお話。

最初の事例がなんと日本のアナ雪の読み聞かせアクション(=スキル。Google ではスキルのことをアクションと呼ぶ)。

You can start with what you already built
続いては、既にあるサービスを活用せよ、というお話。

レシピの活用事例は有名ですが、その他 Web サイトについても情報の一部を自動で紹介する機能を音声で提供できるよ、ということ。また、アプリと連携して声で操作することもできますね、とドーナツの注文事例が紹介されました。

この時会場にドーナツが出現!美味しくいただきました。
Discoverability will require investment
そして最後に、Webサイトからアクションにたどり着けるようにリンクを貼れ、と言うお話。これは大事ですね。まずは知ってもらわないと使えませんからね!

人が変わりまして、Danny Bernstein さんからは、Google Assistant Certification Programs の紹介がありました。AWS認定のような感じですかね。
The Smart Audio Report

The Smart Audio Report は、18歳以上の1002人に対する電話調査の結果。
- 18歳以上のアメリカ国民の24%(約6000万人)がスマートスピーカーを所有している
2019年12月時点のデータで、2017年は18%、2018年は21%。

しかも平均所有台数が 2.6 台!総数は2017年12月で6700万台、2018年12月で1億1900万台、2019年12月で1億5700万台。
- 18歳以上のアメリカ国民の54%が音声コマンドを使ったことがある
- そのうち、24%が毎日音声コマンドを使っている
The Psychology of User Experience Design in Voice
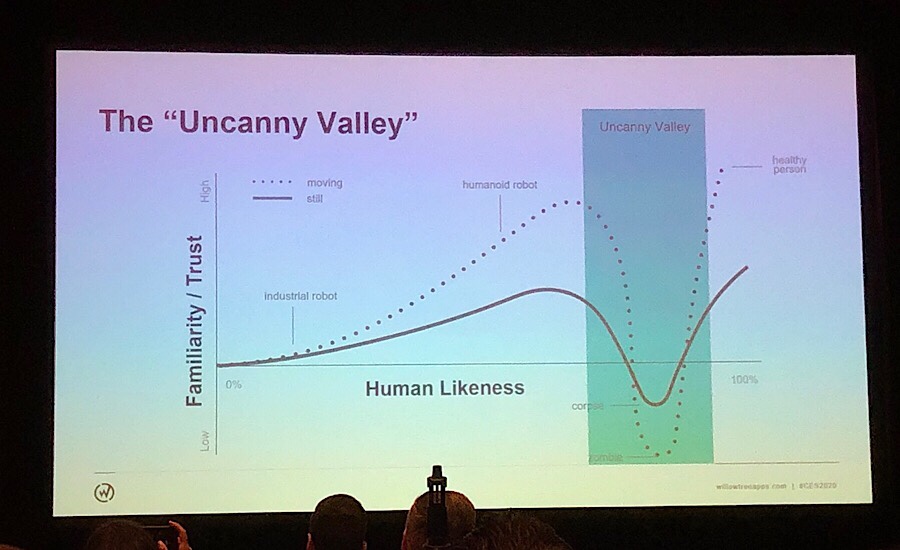
Uncanny Valley(不気味の谷)という現象があり、人間への類似度が極めて高まると、嫌悪感や薄気味悪さなどの負の要素が唐突に表れるらしい。新しい技術に適応することはリレーションシップを構築することと似ているので、人と同じく信頼感が大切になる。
VUIでいえば、アシスタントの認識精度の信頼性と、感情面での信頼性が大事になってくる。(後者でいうと、イントネーションの自然さやアシスタントのキャラクターとしての統一感、自然さなどが含まれると思われる)

なぜ VUI を使うのか、というところに繋がってくるお話。人が機械に情報をインプットさせるとき、Typing だと1分にたった40語しか入力できないが、Speaking だと130語も入力できる。

一方、機械からのアウトプットを得るとき、Listening だと1分あたり130語しか聞き取れないが、Reading だと250語も受け取ることができる。
つまり VUI といえど、画面を使った情報伝達は重要だということ。すべてを音声にするのではなく、画面を有効活用する必要がある。
Build voice not to mimic humans, but to solve human problems.
人間を模倣するのではなく、人間の課題を解決するために音声を使え。
音声でインプットしたら音声で返さないといけないわけではない。人間が求める形で返すべきだ、ということなのだろうと解釈。
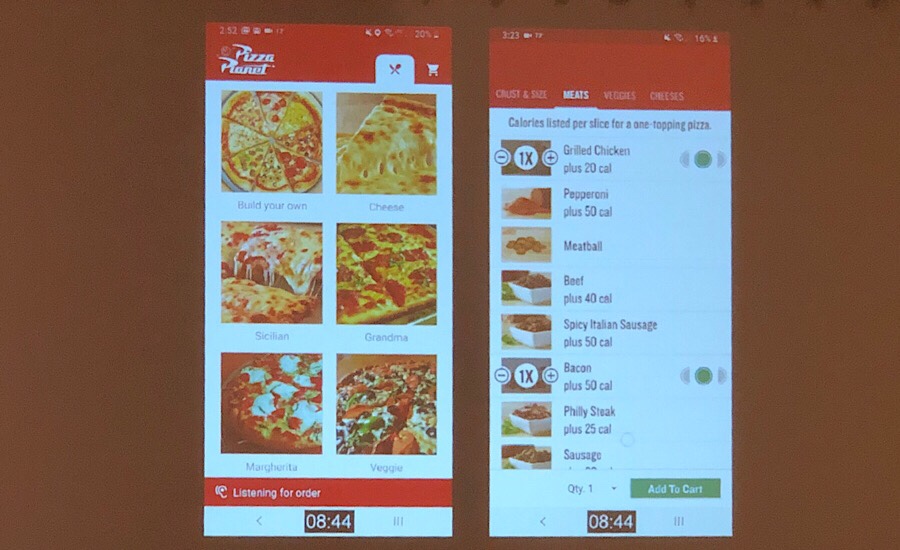
既存のアプリをサポートする形で音声を使うと、こんな複雑な操作も簡単になる、という例。
「Calories listed per slice for a one-topping pizza.」という要求をインプットさせるための GUI は複雑そうですよね。(カロリーとトッピングのフィルタリングに加え、per slice という指定も必要になる)
Voice Assistant on Mobile(Google)
Baris Gultekin さんから、スマホで使う音声アシスタントのユースケースのご紹介。
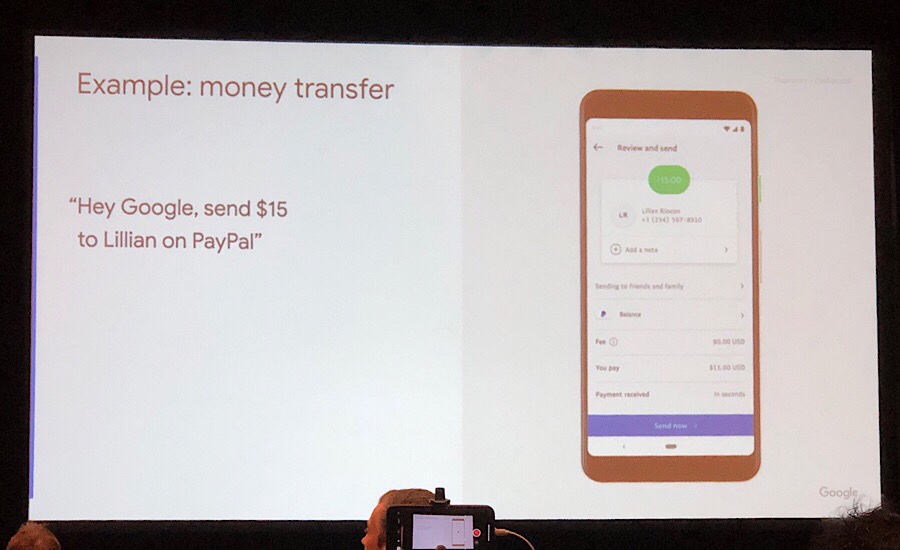
PayPal で送金するときも、「誰にいくら」と言うだけ。
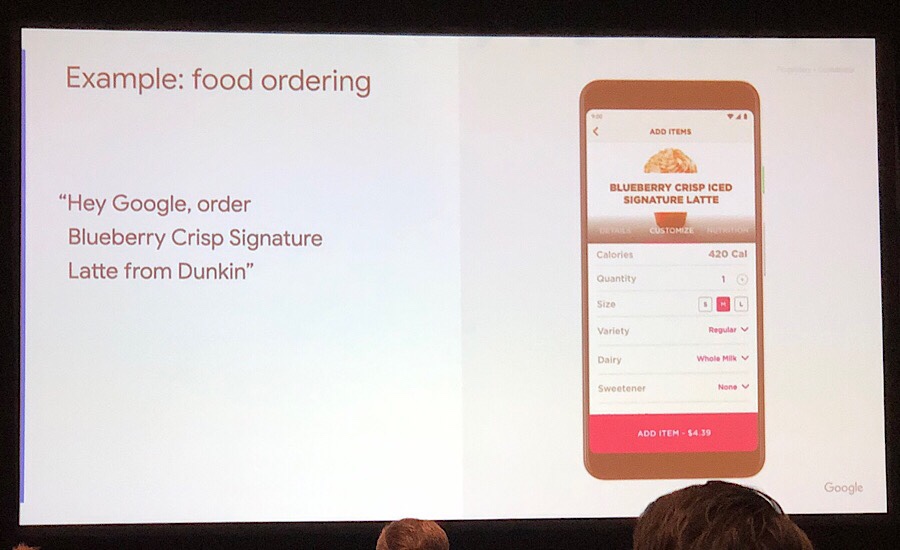
(またでた)Dunkin Dounuts をオーダーする時も、品名を言うだけ。
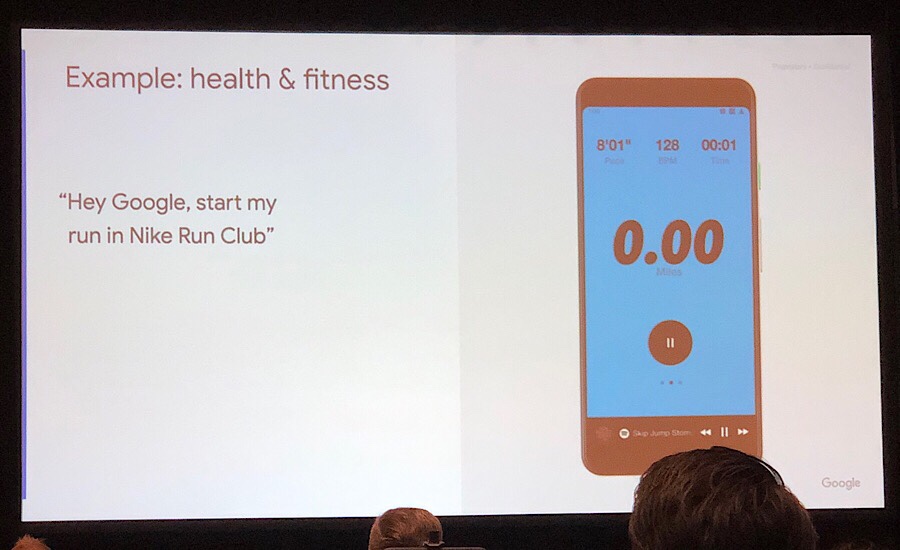
ランニングの計測をするときも、「走り始めるよ!」と言うだけ。これめっちゃ使いたい。画面触るより「よーい…スタート!」という感じで走り始める方が自然だなぁ。
これらが出来るようにするためには、よりたくさんの自然な事例に合わせてアプリを適用させて、価値を広げる必要がある。そのためには、様々な出口を考慮したユーザージャーニーを考えなければいけない(これかなり大変そう)
ドリンク・お菓子のサービス

さすがホテル、ドリンクサービスの準備が手厚い。

(2)へ続く
最新情報をお届けします
Twitter でaoxaをフォローしよう!
Follow @a093_jp